
1/ Latency and throughput are some of the most important focus areas for@SeiNetwork. To get a better idea of the upper bound we could see for throughput while still maintaining low latencies, we ran the following load tests:
1/ 延迟和吞吐量是 @SeiNetwork 的一些最重要的关注领域。为了更好地了解在保持低延迟时,我们可以观察到的吞吐量上限,我们运行了以下负载测试:
2/ Market makers (MMs) are updating their positions whenever prices change. Prices constantly change, so MMs need to update their orders every block. The lower the latency, the smaller the change in prices between blocks, and the less risk MMs need to take on
2/ 做市商 (MMs) 会在价格变化时更新他们的头寸。价格不断变化,因此 MM 需要在每个区块更新他们的订单。延迟越低,块之间的价格变化越小,MM需要承担的风险就越小
3/ If MMs need to take on less risk, they can offer tighter spreads (bid/asks that are closer together), which results in better prices for normal users that place market orders
3/ 如果 MM 需要承担更少的风险,他们可以提供更小的点差(更接近的买入/卖出价),从而为下市价单的普通用户提供更好的价格
4/ Throughput (for an orderbook) is the number of orders that can be processed for any unit of time. The greater the throughput, the more trades that people can place in each block. For a seamless trading experience, exchanges want the highest possible throughput.
4/ 吞吐量(对订单簿)是任何单位时间可以处理的订单数量。吞吐量越大,人们可以在每个区块中进行的交易就越多。为了获得无缝的交易体验,交易所需要尽可能高的吞吐量。
5/ For some benchmarks on latency and throughput,@dYdXv3 currently sees ~1,000 order places/cancellations per second, and@solanamainnet currently sees ~600-700ms block times with ~2500 transactions per second.
5/ 对于延迟和吞吐量的一些基准,@dYdXv3 目前每秒观察到约 1,000 个下单/取消,[@solana](https://twitter.com /solana) 主网目前看到约 600-700 毫秒的阻塞时间,每秒约 2500 笔交易。
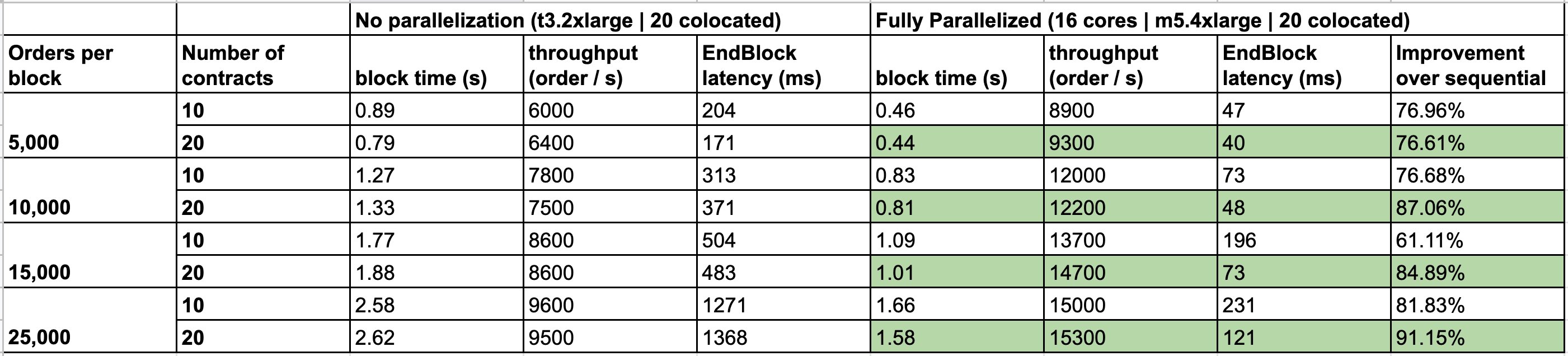
6/ With no parallelism, it was hard to get greater than 8000 orders per second without getting latency that was unacceptably high. A lot of the latency was tied to endblock processing (where we handle order placements/matching/executions), which was CPU bound.
6/ 在没有并行处理的情况下,每秒获得超过 8000 个订单就很难不产生高到无法接受的延迟。很多延迟都与末端区块处理(我们处理订单放置/匹配/执行的地方)有关,这是 CPU 限制的。
7/ Rather than executing transactions one after another (sequentially), we started processing multiple transactions at the same time. While this improves performance, it runs the risk of having nondeterminism between different validators
7/ 我们不是一个接一个(按顺序)执行交易,而是开始同时处理多个交易。虽然这提高了性能,但它有不同验证器之间存在不确定性的风险
8/ Nondeterminism happens when running the same code multiple times doesn’t result in the same output. Ex. if 2 market orders are processed in different orders, user A might pay $10 and user B pays $11 on Node 1, but user A would pay $11 and user B paying $10 on Node 2.
8/ 当多次运行相同的代码不会产生相同的输出时,就会发生不确定性。比如,如果以不同的订单处理 2 个市价单,用户 A 可能在节点 1 上支付 10 美元,用户 B 支付 11 美元,但用户 A 将支付 11 美元,用户 B 在节点 2 上支付 10 美元。
9/ To get around nondeterminism, we were careful to only parallelize orders that weren’t mutating the same state. In practice we ended up processing different markets in parallel (and sequentially processing orders related to the same market based off their ordering in a block)
9/ 为了避免不确定性,我们小心地只并行化没有改变相同状态的订单。在实践中,我们最终并行处理不同的市场(并根据它们在一个块中的排序顺序处理与同一市场相关的订单)
10/ To ensure we don’t parallelize operations to shared state, we require smart contracts to define dependencies they have with other smart contracts. More specifics around how this is handled can be found in our docs and open source GitHub repo
10/ 为确保我们不会将操作并行化到共享状态,我们要求智能合约定义它们与其他智能合约的依赖关系。有关如何处理的更多细节可以在我们的文档和开源 GitHub 存储库中找到
11/ This led to significantly better results. The CPU bound endblock operations saw over 80% improvements in processing time! The greater the number of orders per block that are being processed, the greater the improvements
11/ 这带来了明显更好的结果。 CPU 绑定的末端区块操作的处理时间提高了 80% 以上!每块正在处理的订单数量越多,改进就越大
12/ The parallelized tests were run using 20 colocated validators that were all running m5.4xlarge machines with 16 cores, 64GB RAM, and 100GB NVME storage. Voting power was evenly distributed between all validators
12/ 并行化测试使用 20 个托管验证器运行,这些验证器都运行具有 16 个内核、64GB RAM 和 100GB NVME 存储的 m5.4xlarge设备。投票权在所有验证者之间平均分配
13/ We’re not done yet! We have a bunch of ideas in the works for how we can further improve performance.@Tendermint_CoreABCI++ will give us the flexibility to experiment with a lot of optimistic and parallel processing that we can’t easily do with ABCI
13/ 我们还没有完成!对于如何进一步提高性能,我们有很多想法。@Tendermint_CoreABCI++ 将使我们能够灵活地试验很多乐观和并行处理,虽然我们不能轻易用 ABCI
14/ Please like + retweet if you think these metrics are helpful! We’re planning to publish results after doing our ABCI++ improvements, and can share those as well if helpful. Also huge shoutout to@TonyChenSFfor adding in our parallelization logic + running these tests
14/ 如果您认为这些指标有帮助,请点赞 + 转发!我们计划在完成 ABCI++ 改进后发布结果,如果有帮助也可以分享。另外也大声感谢 @TonyChenSF ,他添加我们的并行化逻辑 + 运行这些测试。
原文地址:https://twitter.com/jayendra_jog/status/1560305088362528768

